Added on:
May 23, 2025
User Prompt
基于CMS的私有化知识库部署方案
```mermaid
graph TD
A[用户前端(浏览器)] -->|提问| B[中台 API 服务]
B --> C[Embedding 模型(bge-m3)]
B --> D[向量数据库(Pg/FAISS)]
B --> E[大模型 API(阿里云百炼 Qwen)]
E --> F[生成答案]
F --> A
subgraph 管理后台
G[CMS] --> H[内容录入/文档管理]
H --> I[向量生成任务]
I --> C
I --> D
end
G -->|节点内容存储| J[(MySQL 数据库)]
B -->|检索日志、QA记录| J
```
Description
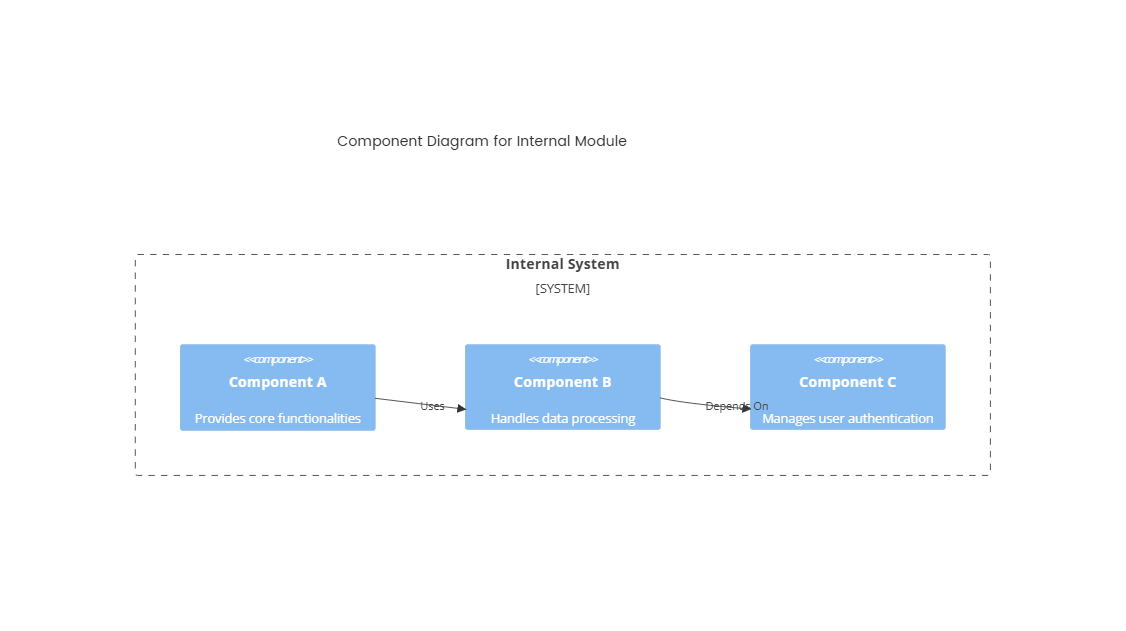
总体架构概览
该方案将知识管理、语义搜索和大语言模型问答整合成一个闭环系统,主要分为三个部分:
- 用户前端与问答流程
- 中台智能检索与生成服务
- 内容管理与向量化处理后台
用户提问流程
A[用户前端(浏览器)] -->|提问| B[中台 API 服务]
- 用户前端(A):浏览器中的交互界面,如聊天窗口、搜索框等。
- 中台 API 服务(B):核心网关,接收问题、负责处理、检索、生成等逻辑。
智能问答流程
- Embedding 模型(C):将用户问题转换为向量。推荐使用 [bge-m3],支持多语言并兼容中文。
- 向量数据库(D):如 PostgreSQL+pgvector 或 FAISS,用于存储已向量化的知识库内容。
- 大模型 API(E):调用阿里云百炼平台的 Qwen 模型进行生成回答,基于检索到的内容进行增强(RAG)。
- 回答生成(F):融合上下文和原始问题,生成自然语言答案返回前端。
管理后台:知识内容的来源与更新
- CMS(G):基于如 Drupal、WordPress 等内容管理系统,实现结构化/非结构化文档的统一管理。
- 内容录入(H):支持手动添加文档、编辑内容、上传 PDF/Markdown 等。
- 向量生成任务(I):定期或实时触发的向量化处理任务,将文档转为语义向量,送入 Embedding 模型并写入向量库。
数据存储与日志追踪
- 所有 CMS 内容通过结构化形式存储于 MySQL 数据库(J)。
- 同时,中台服务也会将用户查询日志、回答记录等写入数据库,便于运营和系统优化。
优势总结
- 私有化部署:全部组件支持本地化运行,保障数据安全与合规性。
- 可控性强:知识源、问答逻辑、模型选型均可定制。
- 模块化设计:CMS + 向量化 + 检索 + 生成环节清晰解耦,易于维护和拓展。
- 支持中文语义搜索:适配中文语境的语义检索与问答生成。